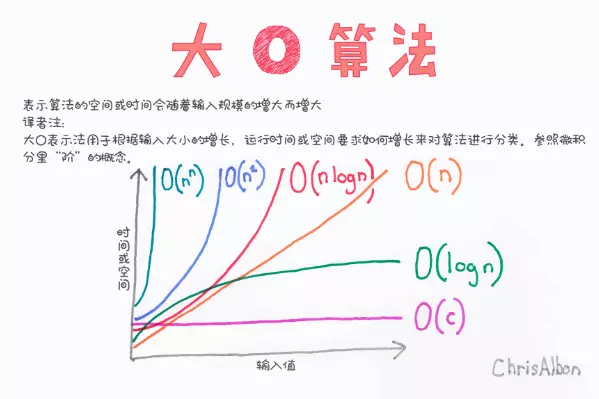
而 是说,计算的复杂度随着样本个数的平方数增长。这个例子在算法里面,就是那一群比较挫的排序,比如冒泡、选择等等。沿着我们刚才的说的那个试卷的例子,等我们找出最高的分数之后,放在一边另起一堆,然后用同样的方法找第二高的分数,再放到新堆上…… 这样我们做 n 次,试卷就按照分数从低到高都排好了。因为有 n 份试卷,所以这种翻试卷,找最高分的行为,我们要做 n 次,每次的复杂度是 ,那么 n 个 自然就是
在比如说构建一个网络,每个点都和其他的点相连。显然,每当我们增加一个点,其实就需要构建这个点和所有现存的点的连线,而现存的点的个数是 n,所以每增加 1,就需要增加 n 个连接,那么如果我们增加 n 个点呢,那这个连接的个数自然也就是 量级了。
无论是翻试卷,还是创建网络,每增加一份试卷,每增加一个点,都需要给算法执行人带来 n 量级的工作量,这种算法的复杂度就是 。
O(nlogn)
然后是 ,这恐怕是常见算法复杂度里面相对最难理解的,就是这个 log 怎么来的。前面那个 n,代表执行了 n 次 的操作,所以理解了,就理解了。